Forecasting und Large Language Models – die beiden Themen sind in vielen Data-Science-Teams aktuell die Themen Nr. 1. In Bereichen wie Absatz- und Materialbedarfsplanung, Produktionsplanung und Bestandsoptimierung liefern präzise Forecasts einen wertvollen Gewinn in Effizienz und Genauigkeit entlang der Supply Chain. In den letzten Jahren hat sich Generative KI (GenAI) zu einer Schlüsseltechnologie entwickelt, die völlig neue Potenziale mit sich bringt. So kann GenAI auf vielfältige Weise auch das Forecasting revolutionieren. In diesem Blogbeitrag erläutern wir am Beispiel von Demand Forecasting, wie man mit GenAI nicht nur noch bessere Prognosen erstellen kann, sondern wie das Thema “Forecasting”, dem viele Personen bisher eher zögerlich begegnet sind, deutlich zugänglicher und verständlicher gestaltet werden kann.
Inhalt:
Der Status quo im Demand Forecasting
Datenanalyse, Mustererkennung und die Bedeutung verlässlicher Prognosen
Forecasting ist eine unverzichtbare Praxis entlang der Lieferkette von Unternehmen und bringt speziell im Demand Planning große Vorteile mit sich. Präzise Forecasts von Materialbedarfen, Absatzzahlen von Produkten und Umsätzen führen insgesamt zu einer präziseren Planung und ermöglichen zudem, potenzielle Trendwenden frühzeitig zu erkennen. Auf diese Art und Weise können Unternehmen ihre Liefertreue verbessern und gleichzeitig ihre Bestände reduzieren, weil sie so weder mehr noch weniger produzieren als nachgefragt wird.
Methodisch funktioniert Demand Forecasting üblicherweise so, dass historische Verbrauchsdaten auf Muster wie Saisonalitäten und Trends analysiert werden, welche schließlich in die Zukunft fortgeschrieben werden – man erhält Zahlen über die voraussichtliche Entwicklung der Bedarfe. Diese Analyse und Prognoseerstellung erfolgt mit Hilfe von geeigneten Vorhersagemethoden, die traditionell aus dem Bereich der Statistik oder des Machine Learnings stammen: Angefangen von einfachen Zeitreihen-Prognoseverfahren wie ARIMA bis zu komplexeren Machine-Learning-Verfahren hat sich eine Bandbreite an Verfahren bewährt. Passend angewendet, führen sie zu guten Ergebnissen.
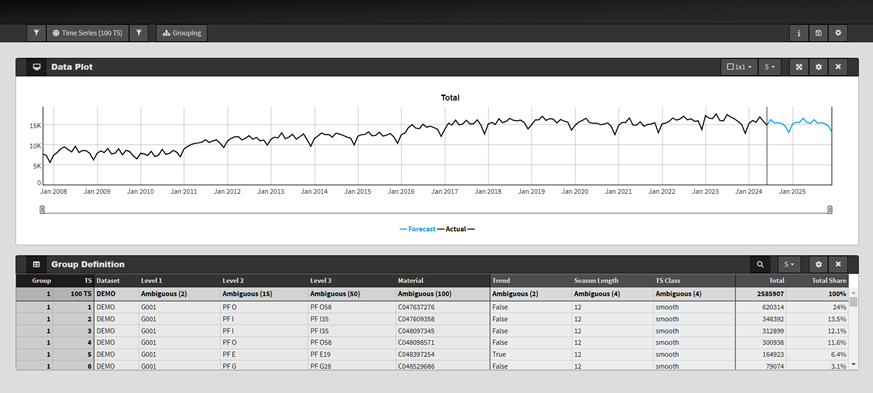
Externe Einflüsse auf die Nachfrage: Die Herausforderung, relevante Faktoren zu identifizieren und integrieren
Neben historischen Verbräuchen wirken sich oft externe Faktoren wie wirtschaftliche Indikatoren, Wetter, Ferien oder Marketingaktionen auf die Nachfrage von Produkten aus. Sie sind häufig die Treiber von Trendwenden und plötzlichen Demand Peaks oder Demand Dips: Eine Marketingaktion hat gefruchtet und hohe Nachfrage hervorgebracht, das aktuell verhaltene Konsumklima führt zu einer verringerten Nachfrage, wenn auch vielleicht erst mit einer Verzögerung von zwei, drei oder vier Monaten. Dass solche Faktoren oft eine Rolle spielen, erschließt sich somit intuitiv. Verständlich, dass der Wunsch aufkommt, sie ins Forecasting einzubeziehen, wobei die erste Herausforderung ist, überhaupt mal die relevanten Einflussfaktoren zu identifizieren. Die zweite ist schließlich, sie in die Prognosemodelle zu integrieren.
Fassen wir zusammen: Für ein fundiertes Demand Forecasting brauchen wir u.a.
- überhaupt mal Forecast-Modelle, die basierend auf Daten Prognosen erstellen können,
- passende Einflussfaktoren, die wir diesen Modellen füttern können,
- gute Erklärungen zu den Ergebnissen, um Transparenz herzustellen und Vertrauen in das datenbasierte Demand Planning zu erzeugen.
Und genau bei diesen Punkten ist generative KI im Zusammenhang mit Forecasting ein Gamechanger. Schauen wir es uns genauer an.
Wie man mit generativer KI zu Forecasts kommt
Globale Zeitreihenmodelle
Generative KI, insbesondere große Sprachmodelle (LLMs), kennen wir alle von ChatGPT, Microsoft CoPilot, Google Gemini, Claude und Co. Die diesen Anwendungen zugrundeliegenden LLMs wurden auf vielen Texten trainiert und haben sich so ein Sprachverständnis angeeignet: Wir geben ihnen Anweisungen (sog. Prompts) in Form von Text bestehend aus Wörtern und Buchstaben in einer gewissen Reihenfolge. Die LLMs setzen diesen Text ziemlich gut fort und liefern uns so Antworten. Im Falle von Forecasting haben wir als Eingabe nun statt Text eine Zeitreihe bestehend aus Zahlen in einer gewissen Reihenfolge. Warum sollte das, was mit Text funktioniert, nicht auch mit Zahlen funktionieren? Man könnte doch ganz viele Zeitreihen hernehmen und damit ein globales, praktisch allumfassendes Vorhersagemodell für Zeitreihen trainieren, wie es z. B. OpenAI mit Texten gemacht hat.
Tatsächlich gibt es solche globalen Zeitreihenmodelle, die auf Transformer-Architekturen basieren und unzählige Zeitreihendaten gesehen haben. Ein Beispiel für ein solches Foundation Model ist das Open-Source-Modell „MoraiAI“. Der Vorteil solcher Modelle ist, dass sie in Sekundenschnelle Vorhersagen liefern können, ohne dass man explizit ein Modell mit individuellen Modellkoeffizienten für die spezifische Zeitreihe trainieren muss. Auch könnte dieser Ansatz spannend sein, wenn wenig Datenhistorie vorhanden ist, um z. B. anderweitig ein robustes statistisches Modell zu trainieren.
Die Meinungen über die Eignung solcher Modelle im Forecasting sind aktuell noch gespalten: Einige Experten glauben, dass Transformer-Modelle Zeitreihen nicht in der gleichen Präzision wie Sprache handhaben können. Andererseits gibt es Befürworter, die darauf setzen, dass Transformer-basierte Methoden klassische statistische Verfahren wie ARIMA oder exponentielle Glättung bald ersetzen könnten. Erste Tests, die wir beispielsweise bei der Demand-Prognose für Absatzmengen durchgeführt haben, haben vielversprechende Ergebnisse gezeigt, auch wenn unsere erste Schlussfolgerung wäre, dass der Ansatz noch optimiert werden muss.
Ein praktikabler Kompromiss könnte darin bestehen, Transformer-Modelle für spezifische Anwendungsfälle wie Demand Forecasting zu trainieren, statt ein universelles Modell für sämtliche Zeitreihen zu entwickeln. So lassen sich die Vorteile der Transformer-Technologie auf spezialisierte Anforderungen zuschneiden, während eine hohe Vorhersagegüte erhalten bleibt.
KI-gestützte Prognose per Chatbot
Besonders innovativ wird es, wenn wir die Sprachfertigkeit von LLMs mit der Prognosefähigkeit von KI-Modellen verknüpfen: Wie wäre es, einen KI-Assistenten zu haben, dem man per Chat seine Prognosewünsche mitgibt, und der einem dann umgehend die gewünschten Prognosen, Analysen, Visualisierungen und Erklärungen ausspuckt? Man muss weder eine bestimmte Software konfigurieren oder bedienen können noch Data Science studiert haben und kann trotzdem zu den gewünschten Ergebnissen kommen:
“Ich übergebe dir eine Zeitreihe mit den monatlichen Umsatzzahlen eines Unternehmens. Bitte erstelle mir Forecasts für die nächsten 12 Monate!”
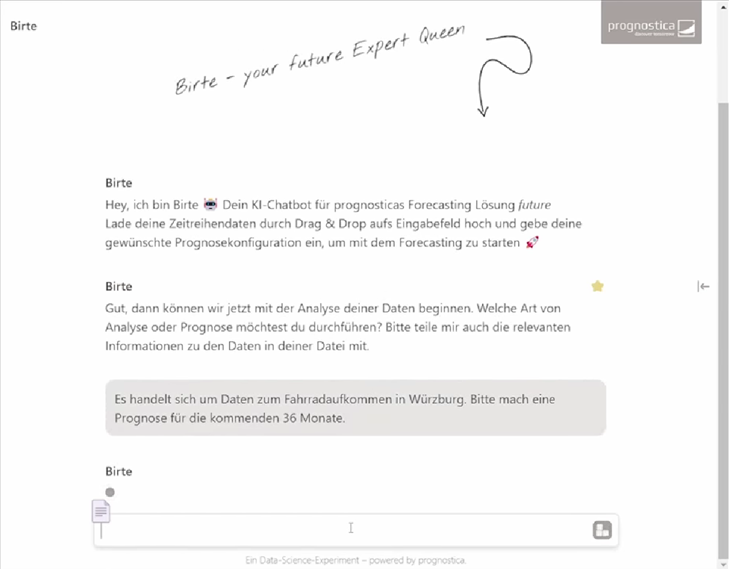
Im Hintergrund arbeitet der Assistent, wendet potenziell die komplexesten Forecasting-Verfahren an, analysiert, vergleicht und gibt schließlich die Ergebnisse zurück, sowohl numerisch als auch grafisch.
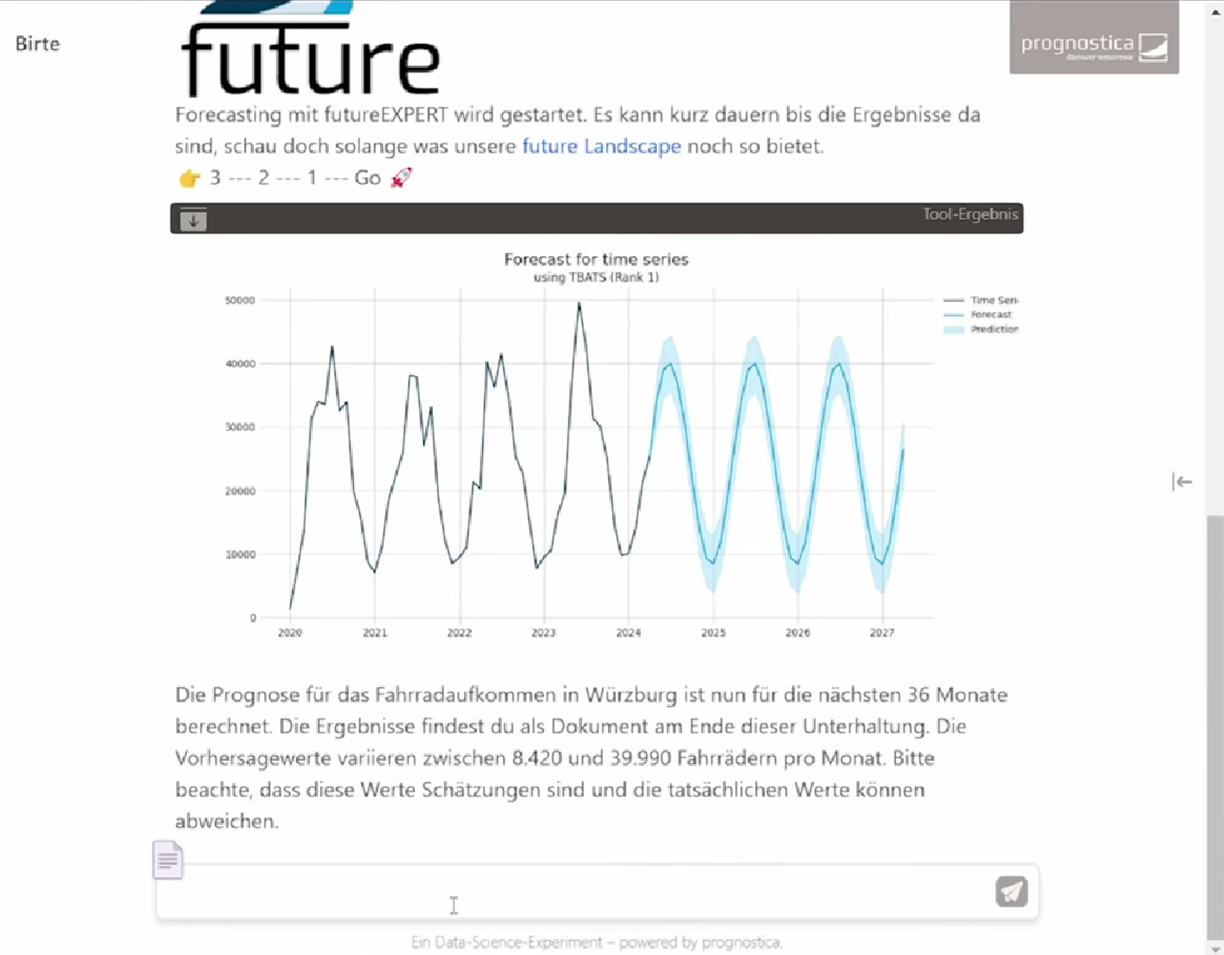
Ein leichterer, einfacherer, intuitiver Zugang zu Forecasting-Möglichkeiten ist doch wohl kaum vorstellbar!
Wie man mit generativer KI zu passenden Einflussfaktoren kommt
Wir haben uns nun angesehen, wie generative KI uns unterstützen kann, überhaupt zu Vorhersagen zu kommen. Sehen wir uns nun an, wie wir die Vorhersagen noch besser machen können, indem wir neben der eigentlichen Historie der Demand-Zahlen noch weitere Einflussfaktoren mit ins Modell nehmen, die auch wirklich eine Erklärung darüber liefern, wie sich die Bedarfe in Zukunft weiterentwickeln. Was wir einem KI-System an Daten und Informationen mitgeben, kann dieses verarbeiten und ein Ergebnis daraus erstellen. Von Daten, die nicht eingehen, oder von unpassenden Inputdaten kann man nicht erwarten, dass sie ein sinnvolles Ergebnis erzeugen.
Einflussfaktoren bewerten: kausale Beziehungen von Scheinkorrelationen unterscheiden können
Schauen wir uns das Beispiel der Anzahl an Regentagen in San Francisco und der Anzahl an Beschäftigten im Druckereigewerbe in Rhode Island an.
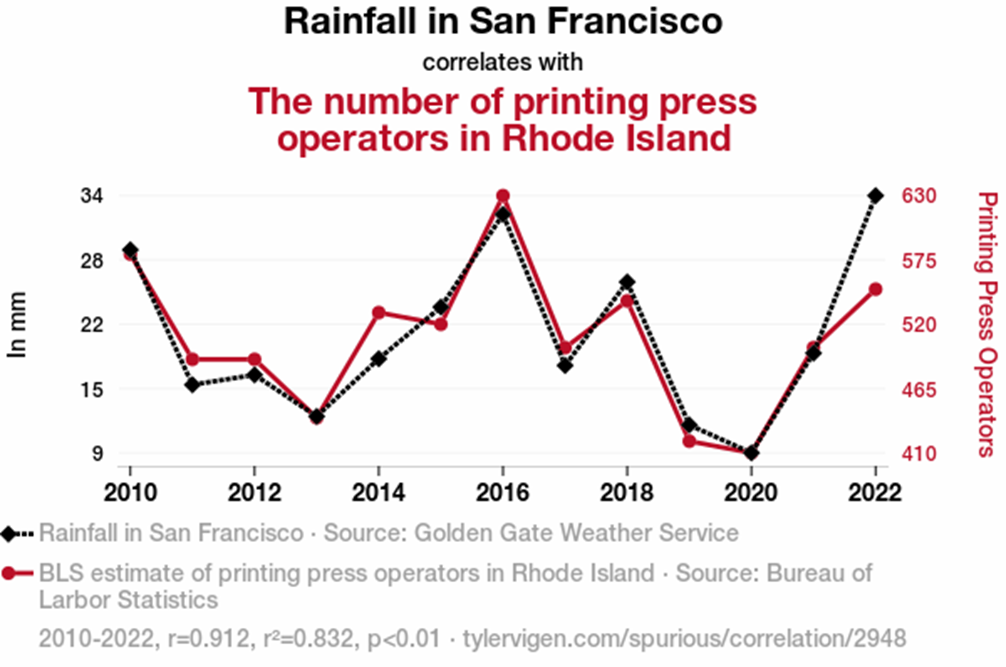
Wenn man die reinen Zahlen ohne Kontext betrachtet, kommt man darauf, dass eine statistische Korrelation vorhanden ist. Von einer logischen oder kausalen Verbindung kann allerdings bei den beiden Größen nicht die Rede sein. Nun besteht aber mit den LLMs die Chance, den Kontext des Anwendungsfalls einzubeziehen. Die Sprachmodelle können auf Allgemeinwissen, spezifisches Branchenwissen, vielleicht sogar auf individuelle Dokumente des Unternehmens zugreifen und damit die Frage angehen: Handelt es sich bei einer identifizierten Korrelation um eine Scheinkorrelation oder liegt eine kausale Beziehung vor?
Zum obigen Beispiel haben wir das Sprachmodell Llama von Meta befragt. Es hat abgewogen und mit sich selbst diskutiert und kam dann zügig zu der Einschätzung: “IT appears that the correlation is most likely a spurious correlation.” Es hat recht.
Eine Automatisierung, sodass eine große Menge an möglichen Einflussfaktoren unter diesem Gesichtspunkt im Zusammenhang mit einer bestimmten Zeitreihe betrachtet werden kann, ist leicht denkbar. Und selbst, wenn die Frage nicht immer ganz eindeutig beantwortet werden kann, sondern die Antwort am Ende mit einem “Vielleicht” versehen ist, ist man mit der inhaltlichen Bewertung der möglichen Einflussgröße bereits einen großen Schritt weitergekommen.
Einflussfaktoren vorauswählen: aus vielen unspezifischen Einflussfaktoren werden wenige passende
Einer ähnlichen Technik kann man sich letztlich auch in folgendem Fall bedienen: LLMs sollen dabei helfen, aus einer großen Auswahl an möglichen Einflussfaktoren diejenigen zu identifizieren, die für den vorliegenden Kontext potenziell passend sind.
Nicht selten werden uns von unseren Kunden in einem bestimmten Anwendungsfall mal eben Zehntausende von möglichen Größen zugespielt, die potenziell als Einflussfaktoren in den Prognosemodellen in Frage kommen. Diese einfach ungefiltert in die Prognosemodelle zu stecken und durchrechnen zu lassen, kann einen immensen Rechenaufwand bedeuten, für den oft gar nicht die Zeit ist. Meist sind in einer solchen Datenbank mit Einflussfaktoren oder Indikatoren eine Reihe an Metadaten in textueller Form vorhanden, z. B. Name, Definition, Einheit, Branche, Quelle oder Region. Diese kann man sich mit Hilfe von LLMs zu nutze machen, um unter allen möglichen Größen diejenigen zu identifizieren, die zum Sachverhalt passen. Im nächsten Schritt würde man dann nur noch diese kleinere Auswahl in Vorhersagemodelle stecken und würde viel Zeit und Rechenaufwand sparen.
Einflussfaktoren konstruieren: aus Text entstehen neue Einflussgrößen
Nachdem wir uns damit beschäftigt haben, bestehende Einflussfaktoren zu bewerten oder vorauswählen, kommen wir nun zur Königsdisziplin beim Einsatz von generativer KI rund um Einflussfaktoren: neue zu kreieren. Oft sind es einmalige oder seltene Ereignisse, die eine riesige Auswirkung auf eine Demand-Zeitreihe haben. Denken wir beispielsweise an Überschwemmungs-Events im Zusammenhang mit der Agrarindustrie oder eine Unterbrechung der Lieferkette aufgrund eines Werkbrands. Mit Hilfe von Grounding bzw. Webscrolling kann man unter der Anwendung von LLMs dahin kommen, dass solche in Form von unstrukturiertem Text vorliegenden Informationen gefunden und in eine strukturierte Zeitreihe umgeformt werden können, welche dann im Anschluss gemeinsam mit der Zielgröße analytisch ausgewertet werden kann.
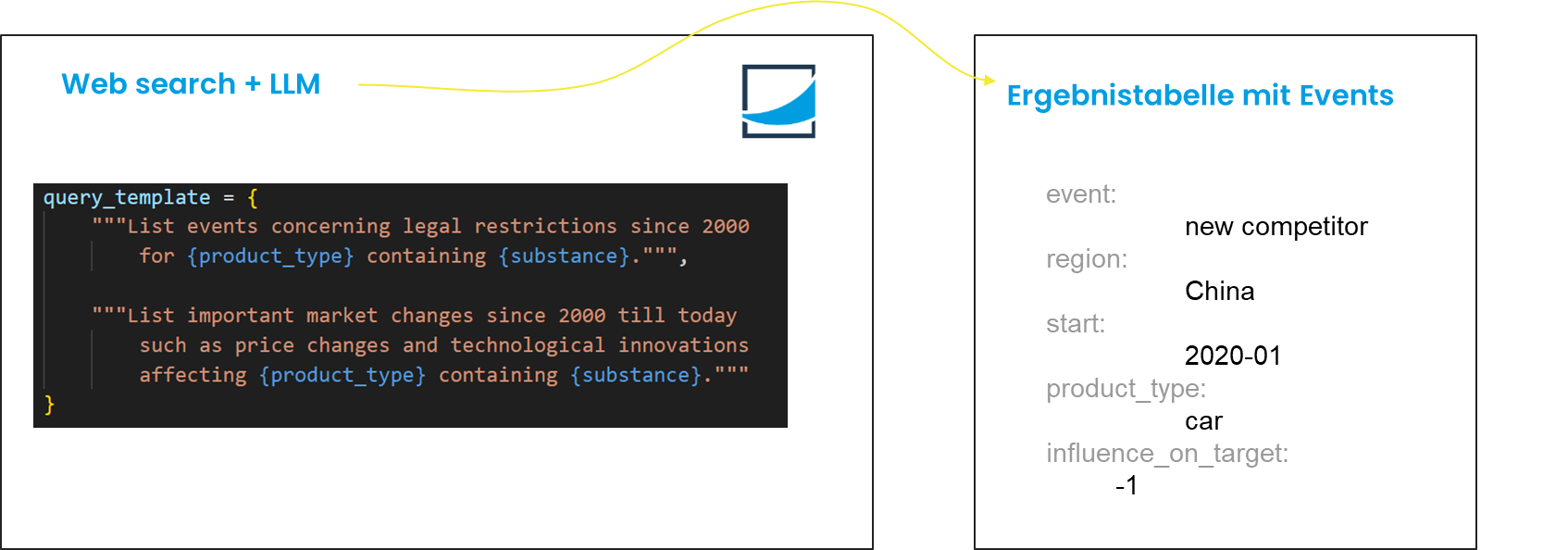
Selbst wenn man es nicht ganz schafft, aus den gefundenen textuellen Informationen numerische Größen zu bilden, die die Prognosen merklich verbessern, so sind diese Informationen dennoch enorm wertvoll für die Interpretierbarkeit und Erklärbarkeit der vorliegenden Daten.
Beispiel: “Warum gingen die Bedarfe 2008 außergewöhnlich stark nach unten? Gab es 2008 irgendwelche Events, die mit unserer Branche in Verbindung stehen und dies bewirkt haben könnten?”
GenAI-Modelle sind in der Lage, derartige Anomalien mithilfe von Textquellen zu erklären.
Wie man mit generativer KI Ergebnisse kommuniziert: individualisiertes Reporting
Nicht zuletzt kann generative KI effektiv zum Einsatz kommen, wenn es darum geht, Forecasting-Ergebnisse zu erklären und zu kommunizieren. Viele Nutzer finden nur schwer einen Zugang zu Forecasting-Ergebnissen, die sie oft als komplex oder intransparent empfinden. So kann es den entscheidenden Unterschied in der Akzeptanz und dem Vertrauen für eine KI-Lösung machen, wenn man dem Nutzer die Möglichkeit zur Verfügung stellt, zu den Ergebnissen in eigenen Worten Fragen zu stellen, die etwa ein individualisierter KI-basierter Chatbot beantworten kann:
Beispiele:
“Wie kommt die im Vergleich zum letzten Jahr hohe Vorhersage für Mai 2025 zustande?”
“Wurde von dem verwendeten Vorhersagemodell ein Trend berücksichtigt?”
Auch könnte man mithilfe von generativer KI ermöglichen, dass verschiedene Stakeholder Forecasts in unterschiedlichen Formaten erhalten: Das Management möchte eine vierteljährliche Zusammenfassung, während der Demand Planner tägliche oder wöchentliche Updates bevorzugt. Generative KI kann das durch individualisierte Reportings und Visualisierungen unterstützen. Ein Chat-Interface könnte es Nutzern ermöglichen, Berichte und Darstellungen gemäß ihren Anforderungen zu generieren – etwa Forecast-Diagramme auf Quartalsbasis für das Management und detaillierte Wochenprognosen für die Planer.
Fazit: Generative KI ist ein Gamechanger in der Zukunft des Forecastings
Generative KI hat das Potenzial, das Forecasting grundlegend zu verändern. Nicht nur stehen mit Foundation Models ganz neue Vorhersagemethoden zur Verfügung, von denen zu hoffen ist, dass sie präziser, schneller und robuster sind als traditionelle Vorhersageverfahren, sondern GenAI birgt einen echten Fortschritt bei der Erklärbarkeit von Ergebnissen sowie dem Einbringen von textuellem, oft unstrukturiertem Kontext in analytische Vorhersagemethoden. Hier liegt großes Potenzial für innovative Ansätze in Unternehmen, beispielsweise im Demand Planning.
Und auch für uns Data Scientists, die wir in vielen verschiedenen Branchen mit Hilfe von Data-Science-Techniken Wert schöpfen können und daher nicht überall Experten sein können, ist es ein spannendes Hilfsmittel. So können wir auch in für uns neuen Branchen und neuen Anwendungen inhaltlich Fuß fassen und Kontext mit Hilfe von generativer KI auf den Grund gehen.
Wir wagen die Prognose: GenAI wird in Zukunft aufgrund der entscheidenden Vorteile bei der Bedienbarkeit und Zugänglichkeit bei sämtlichen Anwendungen rund ums Forecasting nicht mehr wegzudenken sein.