Wer sich dem Thema Predictive Analytics verschreibt, wird mit der Zeit schnell lernen, dass nicht jede Zeitreihe einem Musterbeispiel aus einem Lehrbuch für statistische Prognoseverfahren entspricht. Eindeutige Saison- und Trendkomponenten und minimale Modellierungsresiduen wären schön – doch die Realität ist deutlich komplexer! Ein in der Prognosepraxis häufig vorkommendes Paradebeispiel ist die Klasse der sporadischen Zeitreihen. Mit dem richtigen analytischen Repertoire können belastbare Prognosemodelle aber auch für sporadische Zeitreihen konzipiert werden. Wir stellen im folgenden Artikel einige Vorhersagemethoden und Modellierungsansätze für sporadische Zeitreihen vor und zeigen Situationen auf, in denen solche Methoden und Modelle geeignet sind.
Sporadische Nachfragen machen die Prognose besonders (herausfordernd)
Wer wissen will, wie viele Produkte welcher Art er in den nächsten Wochen oder Monaten produzieren oder im Bestand haben sollte, um eine entsprechende Nachfrage bedienen zu können, muss planen. Historische Absatzzahlen sind hier üblicherweise eine bedeutende Informationsquelle: Wer die Größenordnung sowie gewisse Regelmäßigkeiten wie Saisonalitäten oder Trends darin erkannt hat, kann dieses Wissen in die Zukunft projizieren und rechtzeitig auf Lager haben, was er voraussichtlich verkaufen wird, ohne zu große oder zu kleine Bestände vorzuhalten. Wer nicht auf sein Gefühl vertrauen möchte, kann sich aus einer Reihe heuristischer und mathematisch-statistischer Methoden sowie Methoden aus dem Bereich des Machine Learning und der künstlichen Intelligenz bedienen. Diese können systematisch historische Absätze analysieren und durch intelligente Mechanismen die zum aktuellen Zeitpunkt beste Absatzprognose für die folgende Zeit ermitteln.
Statistisches Forecasting in der Bedarfsplanung ist oft leichter bei großen Nachfragezahlen und regelmäßigen Verläufen des Bedarfs. Wenn ein großer Kundenstamm dahinter steht, sorgt das für einen gewissen Ausgleich von Schwankungen. Interessiert man sich dagegen für Objekte mit einem geringen Kundenstamm, so ergeben sich oftmals Zeitreihen, in der eine sporadische Nachfrage erkennbar ist: In vielen betrachteten Zeitintervallen (z. B. Monaten oder Wochen) existiert eine Nachfrage von 0 (= keine Nachfrage), nur zu den wenigen verbleibenden Zeitpunkten tritt eine positive Nachfrage auf. Bei solchen sporadischen Zeitreihen ist es oftmals unmöglich, mit klassischen statistischen Verfahren, wie z. B. exponentieller Glättung, ein Modell mit klarer Trend- und Saisonkomponente zu schätzen.
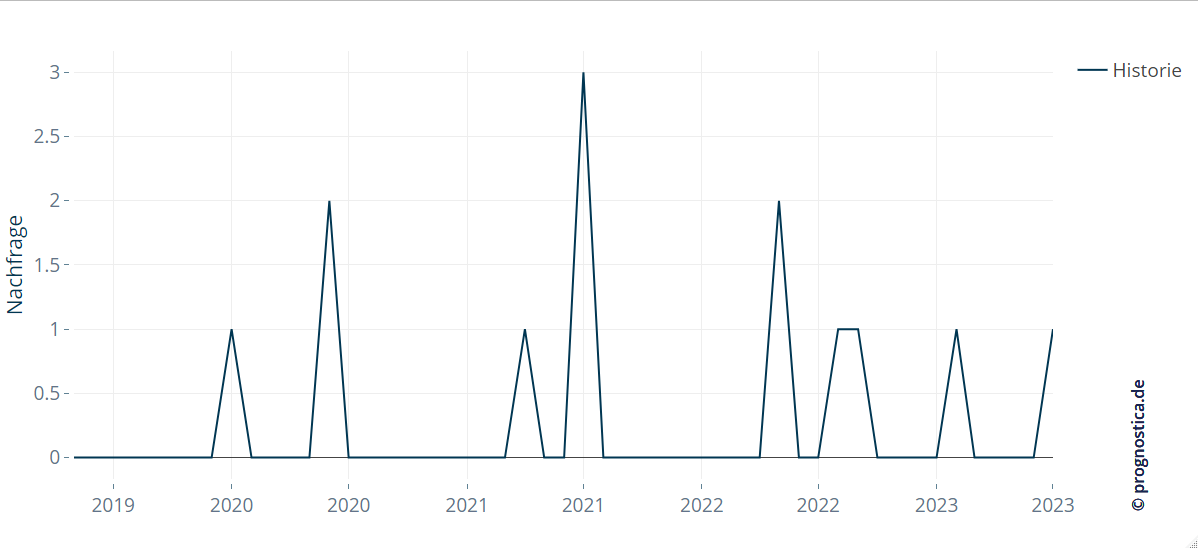
Abbildung 1: Eine typische sporadische Zeitreihe, die nur zu wenigen Zeitpunkten eine von Null verschiedene Nachfrage aufweist.
Aus Sicht des Produzenten sind es aber häufig gerade Artikel mit solchen Nachfragemustern, die nach guten Prognosen verlangen. Und das aus gutem Grund: Schon eine einzelne Bestellung einer bestimmten Menge eines solchen Artikels kann unter Umständen den Sicherheitsbestand angreifen und sorgt potenziell für einen temporären Lieferengpass. Doch für die Herausforderungen der Prognose einer sporadischen Nachfrage existieren spezielle statistische Verfahren, die deren Besonderheiten berücksichtigen.
Sporadische Prognosen bilden das bekannte Nachfragemuster ab
Ein Klassiker bei der Vorhersage sporadischer Nachfrage ist die Croston-Methode. Diese modelliert separat die Höhe der erwarteten Nachfrage und die Zeit zwischen auftretender Nachfrage. Dabei nimmt sie die Veränderung der beiden Größen im Laufe der Zeit in Betracht. In der Prognose weist die Croston-Methode die zu erwartende Artikel-Nachfrage genau demjenigen oder denjenigen Zeitintervallen zu, in denen sie – etwas lapidar gesprochen – am wahrscheinlichsten auftritt.
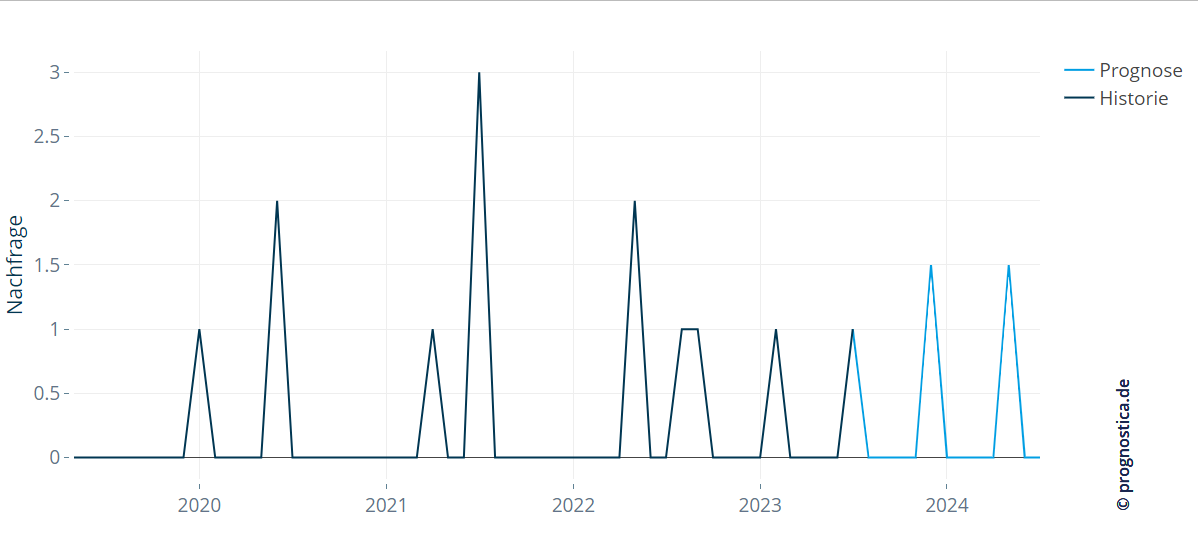
Abbildung 2: Das Croston-Verfahren kann sporadische Prognosen erzeugen, die das sporadische Muster historischer Daten abbilden.
Gemittelte Prognosen für intuitive Planbarkeit
Alternativ zu einer sporadischen Prognose, die die erwartete Nachfrage einzelnen Zeitpunkten zuweist, können mit einer Variante der Croston-Methode auch geglättete Prognosen für sporadische Nachfragen erstellt werden. Dabei werden die im Modell geschätzten Höhen und zeitlichen Abstände der erwarteten Nachfrageereignisse miteinander verrechnet und in der Prognose schließlich eine mittlere Nachfrage für die nächsten anstehenden Zeitintervalle erstellt. Bemerkenswert ist hier, dass die Methode die erwartete Nachfrage gleichmäßig auf die anstehenden Zeitintervalle aufteilt und keine Unterscheidung macht, in welchem Zeitintervall (z. B. in welchem Monat oder in welcher Woche) genau eine Bestellung eines Artikels erwartet wird.
Diese Variante ist der Standard-Output der meisten Planungstools, die die Croston-Methode unterstützen. Obwohl die Vorhersage ein deutlich abweichendes Muster im Vergleich zu den historischen Daten aufweist, entspricht sie damit dennoch eher einer regelmäßigen Produktion oder Beschaffung des Artikels. Dies macht sie intuitiver nutzbar für die Produktions- bzw. Beschaffungsplanung als sporadische Prognosen.
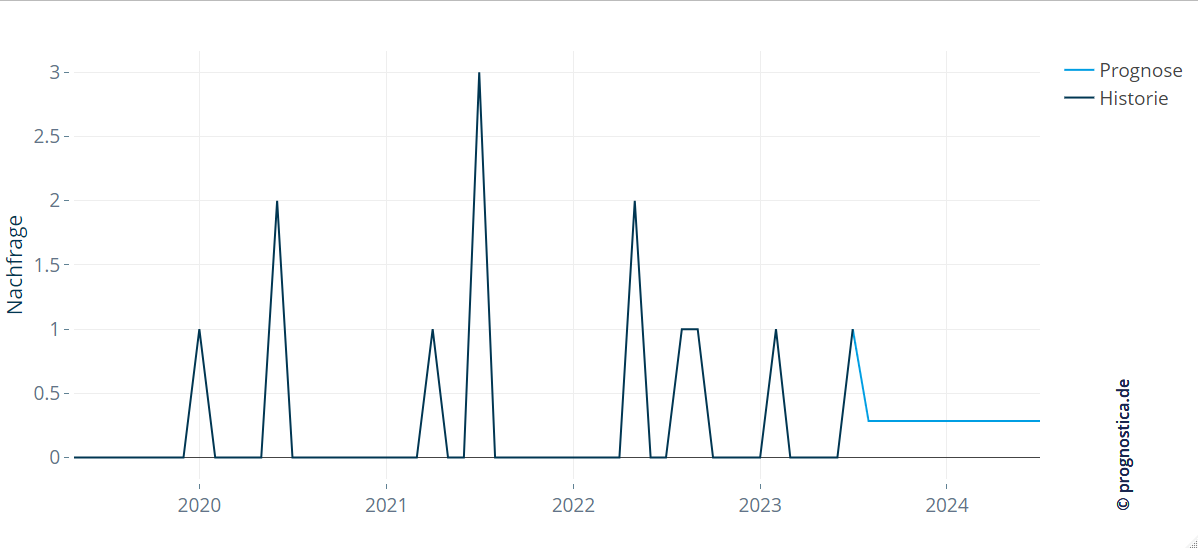
Abbildung 3: Eine Variante der Croston-Methode liefert glatte Prognosen, die die erwartete sporadische Nachfrage gleichmäßig auf zukünftige Zeitintervalle verteilt.
Zwischen den Extremen
Spannend wird nun, den Bereich zwischen den beiden Extremfällen zu betrachten. Die erwartete Nachfrage der kommenden Zeitintervalle wird weder sporadisch noch gleichmäßig auf die Zeitintervalle aufgeteilt. Stattdessen wird denjenigen Intervallen, in denen die Wahrscheinlichkeit für eine Nachfrage höher ist, ein größerer Prognosewert zugeordnet, während in anderen Intervallen entsprechend weniger prognostiziert wird. Um die benötigten Gewichtungen zu bestimmen, kann angenommen werden, dass die diskrete Zufallsvariable “Zeit bis zur nächsten Nachfrage” den Eigenschaften eines stochastischen Erneuerungsprozesses entspricht. Dies bedeutet, dass die Ereignisse unabhängig voneinander eintreten und einer identischen statistischen Verteilung folgen. Indem diese Verteilung basierend auf historisch beobachteten Ereignissen modelliert wird, können die Wahrscheinlichkeiten für zukünftige Nachfragen berechnet werden. Es entsteht ein Vorhersagemuster, das zwischen den beiden Extremen einer konstanten und einer sporadischen Prognose liegt.
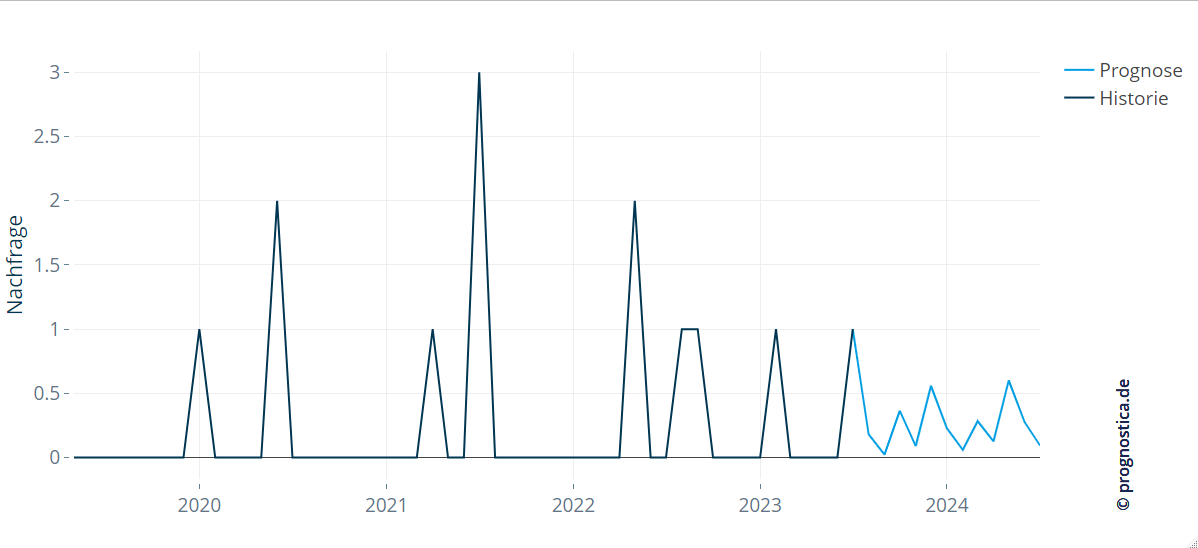
Abbildung 4: Beispiel-Prognose eines Verfahrens, das die Wahrscheinlichkeitsverteilung historischer Nachfragen nutzt, um die Prognose entsprechend der erwarteten Eintrittswahrscheinlichkeiten zu modellieren.
Mustererkennungsverfahren identifizieren komplexere Gesetzmäßigkeiten der Nachfrage
“Erfahrungsgemäß wird im Januar keine Nachfrage auftreten. Falls doch, so trifft auch im Februar noch eine Bestellung ein, im März dann aber sicher nicht mehr.”
Dieses fiktive Beispiel zeigt einen Ausschnitt aus dem Nachfragemuster eines Artikels, welcher beispielsweise von einer jährlichen Saisonkomponente im Vorhersagemodell allein nicht erfasst werden könnte, obwohl bestimmte Monate im Jahresverlauf bei der Nachfrageplanung eine Rolle spielen. Stattdessen hängt die zukünftige Nachfrage stark von Art und Umfang zuvor aufgetretener Nachfrageereignisse ab.
Wer derartige Muster abbilden möchte, dem steht eine ganze Bandbreite weiterer spannender Verfahren aus dem Bereich des Machine Learning zur Vorhersage zur Verfügung. Verfahren wie Entscheidungsbäume (z. B. Classification and Regression Trees oder Random Forests), Support Vector Regression oder neuronale Netze können potenziell auch komplexe, mit bloßem Auge oft nicht sichtbare Muster erkennen und in die Zukunft projizieren. Wichtig ist, sie insbesondere im Hinblick auf die zeitlichen Abhängigkeiten von Bestellungen geeignet anzuwenden. Machine-Learning-Verfahren sind über einen Zeitverlauf meist nicht per se informiert, sondern diese Information muss ihnen in geeigneter Art und Weise in Form von Einflussfaktoren gesondert mitgegeben werden. Dies setzt eine ausreichend lange Datenhistorie voraus, damit die Verfahren in der Lage sind, die entsprechenden Muster zu erlernen, sowie die Einflussfaktoren auszuwählen, für die tatsächlich ein Effekt auf das Nachfragemuster nachgewiesen werden kann. Der Mechanismus der Kreuzvalidierung, geeignet auf sporadische Zeitreihen angewandt, kann hierbei sehr nützlich sein.
Die untenstehende Abbildung 5 zeigt, dass das Muster “falls im Januar eine Nachfrage nach einem Ersatzteil auftritt, so wird es auch im Februar Nachfrage geben” im obigen Beispiel erkannt und korrekt prognostiziert wurde.
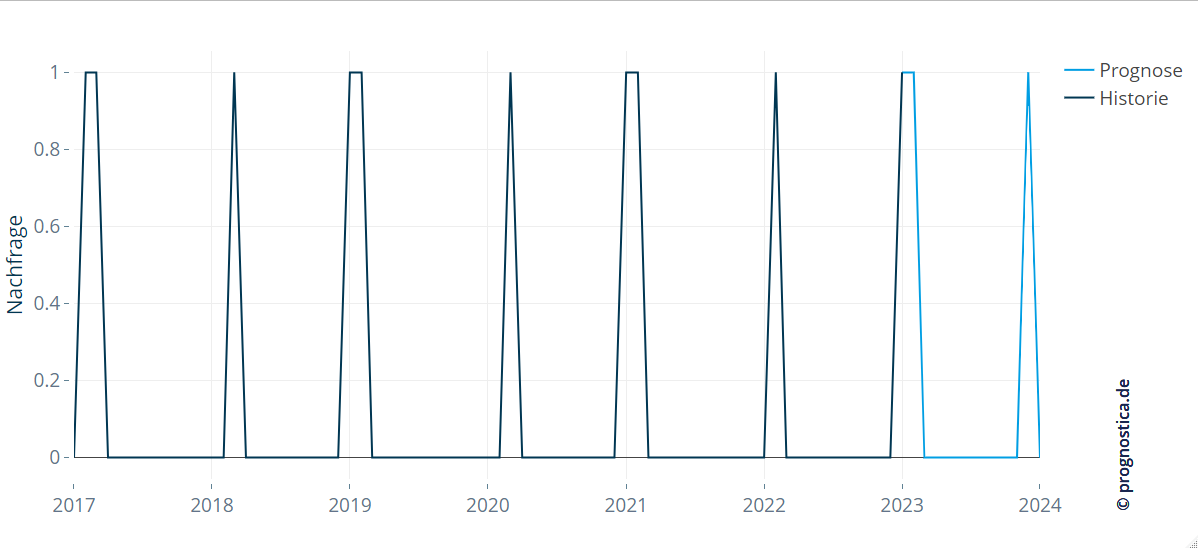
Abbildung 5: Machine-Learning-Verfahren können bei ausreichender Datenhistorie auch komplexere Muster in den Daten modellieren.
Nutzung von Zusatzinformationen bei sporadischen Nachfragen
In vielen Fällen ist es sinnvoll, für die Prognose nicht nur die eigene Datenhistorie heranzuziehen, sondern den Prognosemodellen Zusatzinformationen mitzugeben. Dies eignet sich beispielsweise bei Vorliegen von nur wenigen historischen Daten, wo es in der Regel schwer oder gar unmöglich ist, komplexere statistische Prognosemodelle oder Machine-Learning-Verfahren zu schätzen. Reichert man weniger komplexe, statistische Vorhersageverfahren mit zusätzlichen Modellannahmen an, so sind solche Verfahren durch diesen Kickstart in der Praxis oft in der Lage, auch aus kürzeren Historien aussagekräftige Ergebnisse zu erzielen.
Beispiel einer solchen Modellannahme: “Wenn es ein Muster gibt, dann ein sich alle 12 Monate wiederholendes.”
Das Beispiel zeigt, dass, insbesondere bei sehr kurzer Datenhistorie, die Nutzung vorhandener Zusatzinformationen und ihre angemessene Integration in die Prognose zunehmend an Bedeutung gewinnen. Im Beispiel ist es das Wissen um eine vorhandene Jahressaison. Produktbezogene Zusatzinformationen werden oft von den Betrieben gepflegt oder sind den Mitarbeitern (z. B. Produktplanern, Verkauf etc.) bekannt.
Beispiele für verwertbare Informationen zur Prognose von Ersatzteilen sind:
- Wissen um saisonale Effekte,
- Lebenszyklus eines Produktes,
- Vorgänger- und/oder Nachfolgeprodukte,
- hierarchischer Kontext (z. B. Ausgangsprodukt zu weiter verarbeitetem Artikel),
- offene Bestellungen,
- Inaktivitätsinformationen zu Kunden oder
- externe Indikatoren.
Um solche Zusatzinformationen in der Prognose nutzen zu können, bedarf es oft dem jeweiligen Fall angepasster Datenverknüpfungen und geeigneter Vorhersageverfahren. Dieser Blog-Artikel zu Small Data beleuchtet das Thema “kleine Datenmengen” und die damit verbundenen Herausforderungen und Möglichkeiten genauer.
Am Anfang und Ende des Lebenszyklus von Produkten: ein Beispiel für die Nutzung von Zusatzinformationen in der Prognose
Normalerweise haben Artikel einen endlichen Lebenszyklus in ihrer Produktion. Am Anfang einer Neueinführung eines Geräts und auch am Ende können Prognosen, die nur auf der Datenhistorie des Produktes selbst basieren, schnell ungenau werden, etwa wenn der Bedarf mit einer schnellen Markteinführung des Produkts zu Beginn eines Lebenszyklus schnell steigt. Für exakte Bedarfs- und Bestandsprognosen eines Produktes können dementsprechend Informationen zu dem zugehörigen Lebenszyklus in mehrfacher Hinsicht essentiell sein.
Für belastbare Prognosen eines Artikels, der nach seiner Einführung noch am Anfang seines Lebenszyklus steht und daher eine sehr kurze Datenhistorie hat, kann es vorteilhaft sein, sich mit Datenhistorien von Artikeln zu behelfen, die ähnliche Eigenschaften wie der untersuchte aufweisen. Indem die bekannte Historie ähnlicher Artikel als Einflussfaktor in dem Vorhersagemodell des fokussierten Artikels verwendet wird, kann sich das neue Vorhersagemodell etwas von dem alten Verlaufsmuster abschauen. Gerade bei Produkten mit sehr kurzen Lebenszyklen (z. B. jährlich neue Modelle eines Smartphone-Herstellers) kann die multiple Verkettung von Vorgänger- und Nachfolgeprodukten einen immensen Zugewinn an Prognosegüte bringen. Ebenso ist am Ende besondere Vorsicht geboten: Auch wenn es schon einen Nachfolger gibt, kann das eigentliche Produkt noch einige Zeit nachgefragt werden. Die Nachfrage läuft aber sukzessive aus. Hier kann es hilfreich sein, die Basis-Prognose durch passende Einflussfaktoren oder eine modellierte Ausblendung dem tatsächlich erwarteten Auslauf anzugleichen (Stichwort “Phase-out-Management”).
Die Auswahl des richtigen Verfahrens
In den vorhergehenden Abschnitten wurde klar: Gute Prognosen für sporadische Nachfragen sind essentiell, und es gibt eine Vielzahl an möglichen Prognoseverfahren, die zur Verfügung stehen - doch wie wählt man das passende Verfahren für die vorhandenen Daten aus?
Um das Verfahren zu finden, das die präzisesten Prognosen für ein Vorhersageobjekt (z. B. die Nachfrage nach einem bestimmten Artikel) erzeugt, ist es üblich, zunächst ein Kollektiv von passenden Verfahren auszuwählen. Expertenwissen über das vorherzusagende Produkt, seine Eigenheiten, seine Lebensphase sowie potenziell zu verwendende Einflussfaktoren darf hierbei nicht vernachlässigt werden. Geeignet genutzt, kann das Expertenwissen die Algorithmen wesentlich anreichern und die Praxistauglichkeit von Prognosen verbessern.
Auf quantitative Weise können mehrere geeignete Kandidaten mit Hilfe des folgenden Mechanismus evaluiert werden: Die Forecasting-Performance eines jeden einzelnen Verfahrens wird für ein individuelles Vorhersageobjekt auf einem vorab definierten, ausreichend langen Zeitraum in der Vergangenheit ausgewertet. Die dabei am besten abschneidenden Verfahren sollten für die Erzeugung von Vorhersagen in Erwägung gezogen werden. Zusätzliche Bewertungskriterien können sinnvollerweise je nach Fall und verwendeter Vorhersagemethoden Beachtung finden und die finale Verfahrenswahl beeinflussen.
Ein entscheidender Aspekt in diesem Zusammenhang: Was heißt es eigentlich, am besten abzuschneiden? Wie lassen sich die Prognosen der einzelnen Verfahren zur Bewertung geeignet quantifizieren? Dazu kann man sogenannte Gütemaße heranziehen, die eine gegebene Prognose durch passende Referenzdaten bewerten. Eine Einführung zu verschiedenen geläufigen Gütemaßen geben wir in diesem Blog-Artikel zu Prognosegüte. Hier sind insbesondere die Gütemaße PIS oder SPEC zu nennen, die speziell auf die Eigenheiten sporadischer Zeitreihen ausgelegt sind.
Abschätzen von Unsicherheiten in der Prognose
Egal wie gut die Prognose einer Produkt-Zeitreihe ist, letztendlich wird sie sich mehr oder weniger von der tatsächlich eingetretenen Nachfrage unterscheiden. Dementsprechend ist es auch bei Prognosen bezüglich sporadischer Zeitreihen wichtig, neben den Punktprognosen auch die Unsicherheiten dieser Prognosen zu bewerten (um beispielsweise passende Sicherheitsbestände einzukalkulieren).
Ein wesentlicher Indikator zur Bewertung der Prognoseunsicherheit ist die Prognosevarianz. Viele statistische Vorhersageverfahren liefern die Prognosevarianz direkt mit. Wo modellbasierte Varianzen nicht existieren - z. B. bei den oben angesprochenen Mustererkennungsverfahren - kann (bei ausreichend langer Datenhistorie) auf die empirische Varianz zurückgegriffen werden, um etwa den MAD (Mean Absolute Deviation) zu berechnen. Die oben angesprochenen Validierungsmechanismen liefern entsprechende nützliche Ergebnisse mit. Die evaluierten Unsicherheiten lassen sich in Form von Prognoseintervallen (auch: Prädiktionsintervallen) meist sehr gut visualisieren, können aber im Falle von sporadischen Zeitreihen auch schnell mal relativ breit werden.
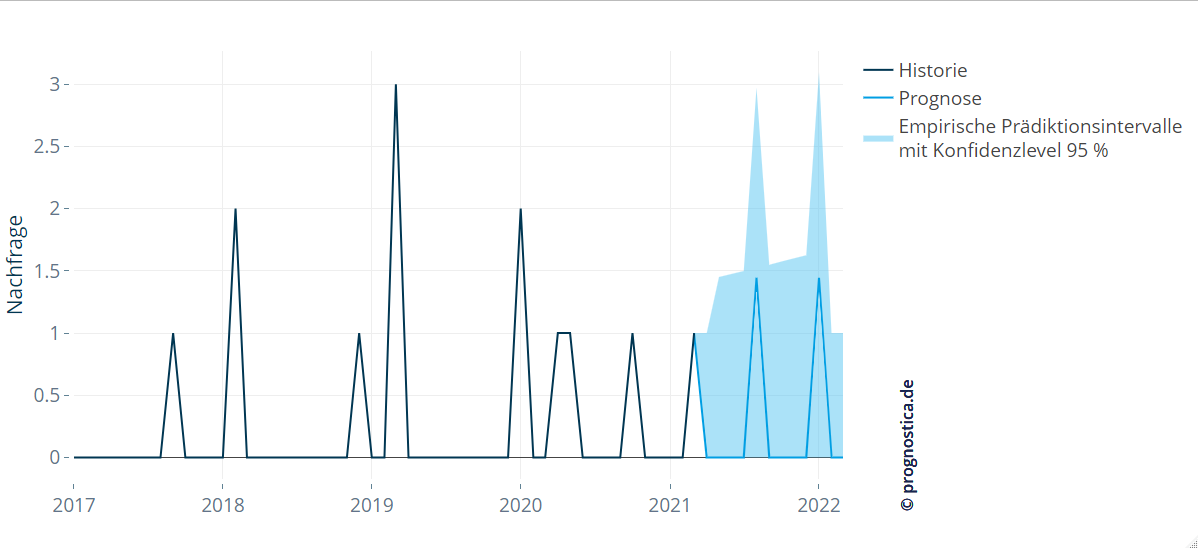
Abbildung 6: Prognoseintervalle quantifizieren die Prognoseunsicherheit; hier bestimmt mittels empirischer Verfahren.
Mit geeigneter Methodik und Anwendungsexpertise zu guten Bedarfsprognosen für sporadische Zeitreihen
Gute Bedarfsprognosen sind essentiell für eine optimale Planung, um auf der einen Seite hohe Lagerkosten durch Überproduktion und auf der anderen Seite entgangene Verkaufschancen durch fehlende Produkte zu vermeiden. Gerade bei Produkten, deren Historien oftmals durch sporadische Nachfragen oder kurze und dynamische Lebenszyklen geprägt sind, ist die Wahl passender Methodik besonders wichtig. Durch Anreicherung der Datenhistorie mit weiteren zur Verfügung stehenden Zusatzinformationen und die Integration dieser in die Prognoseverfahren, können generierte Prognosen signifikant verbessert werden. So lassen sich auch sporadische Bedarfe treffsicher und automatisiert planen.
Lust bekommen, selbst mal Vorhersagen für die eigenen sporadischen Daten zu erzeugen?